AI 早报 2026-01-16
概览
产品应用
- Google 推出 AI Mode 与 Canvas 升级搜索协作能力 ↗
#1
其他
- AIMesh ↗
#2 - DeepMMSearch-R1 ↗
#3 - Galaxy AI ↗
#4 - Grok ↗
#5 - Grok 4.20 ↗
#6 - Manzano ↗
#7 - OpenCode Black ↗
#8 - Step-Audio-R1.1 ↗
#9 - Step3-VL-10B ↗
#10 - 千问App ↗
#11 - 维基媒体基金会 ↗
#12
产品应用
Google 推出 AI Mode 与 Canvas 升级搜索协作能力 #1
谷歌将于2026年1月14日发布指南,用AI模式和Canvas工具规划旅行,应对复杂搜索需求
Google 推出全新 AI Mode 架构及核心工具 Canvas,推动 Search 向生成式协作平台演进。Canvas 提供结构化交互界面,支持用户通过提示词与 AI 深度协作,实现行程建议、地点筛选与路线编排等功能。该工具允许实时编辑与重组内容,提升对复杂任务(如旅行规划)的控制力。AI Mode 可动态响应用户反馈,优化交通衔接、住宿与景点安排等细节。目前,该功能已在旅行规划场景中落地,支持用户在单一界面完成从构思到执行的全流程操作。
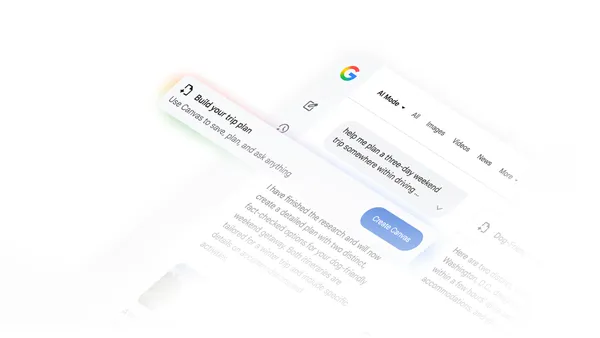
相关链接:
其他
AIMesh #2
2026年1月15日,国内软件定义存储厂商XSKY星辰天合正式发布了其专为AI场景打造的全栈AI数据方案AIMesh。该方案旨在针对性地解决AI训练与推理过程中的关键性能瓶颈,帮助企业构建高效且可控的AI工厂。XSKY CEO兼联合创始人胥昕在发布中阐述了其核心观点:在大模型时代,算法趋向同质化,企业真正的差异化竞争优势来源于其自身独有的私有数据。因此,企业的需求不仅在于高速的存储,更在于一个能够安全、私有化地在内部将数据转化为智能的数据底座。基于此判断,XSKY同时宣布其战略重心从传统的“信息技术(IT)”全面转向“数据智能(Data Intelligence)”,致力于构建一个中立且解耦的“数据常青”底座。
在技术层面,AIMesh旨在突破制约AI效率的“三堵墙”。胥昕指出,当前在大量训练与数据工程场景中,GPU利用率常因I/O等待而被拉低至30%至50%,极端情况下甚至更低。这“三堵墙”具体表现为: 第一堵是“IO墙”,其成因是计算单元的吞吐速度远超存储读写速度,导致算力空转。 第二堵是“内存墙”,由模型参数爆发式增长与GPU显存有限容量之间的物理矛盾所致。 第三堵是“数据重力墙”,指的是数据体量呈几何级数增长导致跨地域流动成本高昂,从而形成新的数据孤岛。
AIMesh方案被定位为面向“AI工厂”的数据与内存网络,由三大核心组件构成,分别应对上述挑战: 首先是训练数据网MeshFS。这是一个面向AI训练场景的并行文件系统。它具备全协议兼容、线性性能与企业级智能分层能力,核心目标是将训练数据高速供给GPU,缓解因I/O等待造成的算力浪费。根据XSKY提供的实测数据,MeshFS在顺序读带宽上相比行业通用方案实现了30%的提升,而顺序写带宽的提升幅度超过50%。
其次是全局对象网MeshSpace。这是一个面向EB级非结构化数据的全局数据平台。它通过统一的全局命名空间,实现了跨地域、跨异构存储的数据流动与统一纳管。该组件升级了其XScale引擎,实现了单桶百万OPS的效能,即单个对象存储桶每秒可支持高达一百万次的对象写入操作。在性能指标上,MeshSpace的大块写性能提升了近50%,并且延迟降低了30%。
第三是推理内存网MeshFusion。这是一个面向AI推理中KVCache的“持久化内存”解决方案。其技术原理是将服务器本地的NVMe SSD转化为L3级外部内存,从而近乎无限地扩展现有系统的上下文窗口支持能力。XSKY称,使用该方案的硬件成本仅为传统纯DRAM方案的1%。实测性能数据显示,其与纯DRAM的性能差距被控制在10%以内;在高并发场景下,其吞吐量能够实现线性增长;在资源受限状态下,甚至能实现20%的性能反超,从而显著降低AI推理的硬件投入成本。
在战略与合作伙伴层面,XSKY强调了其“开放解耦”与“绝对中立”的原则。胥昕透露,近三年来XSKY保持了超过50%的市场增长,全闪存产品占比已达35%,其服务已支撑超过280个容量超过10PB的超大型集群,并突破了单集群百PB的容量门槛。针对算力与云环境快速迭代的现状,AIMesh的设计坚持不绑定任何特定的算力平台或云环境。这意味着,无论客户选择英伟达、昇腾、寒武纪、摩尔线程还是沐曦等不同算力,也无论是在私有云还是混合云环境中部署,AIMesh方案都能提供统一、标准化的数据服务。胥昕认为,算力硬件遵循的摩尔定律正在失效,每一代新硬件的生命周期可能只有3到5年,而数据资产的价值需要延续10年至20年。因此,XSKY的目标是“用确定性的数据能力,去对抗不确定性的技术变革”,这一理念即被称为“数据常青”。
XSKY的产品已获得多家行业客户的验证。上海大模型厂商MiniMax已将其PB级的核心训练数据与推理模型数据稳定运行在XSKY平台上。MiniMax方面认为,MeshSpace的全局命名空间是解决混合云环境下“数据孤岛”问题的潜在方案,而MeshFS的高吞吐与低延迟特性将有效保障其训练效率。在硬件生态合作上,XSKY与英特尔的合作已持续超过十年。双方曾进行技术共创,XSKY入选过英特尔精选解决方案,并成为英特尔CPU新品首发伙伴。具体而言,MeshFS针对英特尔至强处理器指令集进行了深度优化,而MeshFusion则充分利用了NVMe SSD的性能。这种“软硬协同”的合作还在继续深化,目前双方正联合预研基于CXL技术的内存池化方案。此外,云基础软件提供商云轴科技ZStack也在新一代智算平台的建设上与XSKY合作,其AIOS产品与AIMesh的设计理念高度契合。
随着大模型的持续演进,其背后的数据规模与处理复杂度急剧攀升,存储系统在AI计算体系中的重要性日益凸显。英伟达CEO黄仁勋曾预测,由AI驱动的存储市场“未来很可能成为全球最大的存储市场”。目前,XSKY的产品已服务于超过3000家客户,并在诸如金融生产系统、运营商的海量并发业务场景以及自动驾驶算力中心等对性能与可靠性有极高要求的领域实现了规模化落地应用。
链接列表: https://zhidx.com/p/528974.html






相关链接:
DeepMMSearch-R1 #3
科技媒体 Appleinsider 在当地时间 1 月 15 日报道了 Apple 发布的重磅研究论文,详细介绍了一款名为 DeepMMSearch-R1 的 AI 模型。该模型的核心研究目标是重点优化 AI 在复杂视觉场景下的搜索逻辑,通过引入“图像裁剪”技术来有效遏制 AI 在处理此类任务时产生的幻觉问题。
目前的 AI 模型在处理包含复杂视觉信息的问题时,经常会出现“答非所问”或“漏看”关键细节的情况。例如,当用户针对一张包含多个物体的图片提出如“图中左上角那只鸟的最高时速是多少”这类复合问题时,传统模型由于无法在全局视野中精准聚焦到特定的局部细节,往往会直接读取图片的大致信息或给出错误的平均数据,导致结果失真。
为了解决这一痛点,Apple 为 DeepMMSearch-R1 引入了一套独特的视觉定位工具 Grounding Tool。该工具赋予了模型主动裁剪图片的能力,其运作逻辑是首先剔除图片中的无关干扰信息,通过裁剪操作将视野聚焦于微小目标之上进行精准识别。在完成精确的目标定位后,模型才会携带识别出的局部特征进行针对性的网络搜索验证,多步骤的确认流程确保了最终答案的事实准确性。
在算力消耗与效率控制方面,研究人员意识到频繁启用裁剪功能会占用大量计算资源。为此,DeepMMSearch-R1 采用了“监督微调(SFT)+ 在线强化学习(RL)”的组合训练方案。其中,SFT 阶段的主要任务是教会模型识别必要的使用场景,即实现“不乱剪”,确保模型仅在必要时才调用视觉定位工具。而 RL 阶段则专注于优化工具调用的整体效率,提升模型的决策速度。
根据公开的论文测试数据,DeepMMSearch-R1 在处理需要精准图文对应关系(Multimodal Alignment)的问题时表现卓越。其测试结果显著优于现有的检索增强生成(RAG)工作流以及常规的基于 Prompt 的搜索 Agent。研究指出,该模型成功克服了 AI 在进行常识性事实检索过程中常见的“偷懒”现象,即指模型在未能完全理解图片细节的情况下便草率给出答案的行为。
这项研究的完整论文题目为《DeepMMSearch-R1: Empowering Multimodal LLMs in Multimodal Web Search》,其技术路径为未来 Apple 各类设备上的多模态交互提供了新的技术储备,进一步强化了 AI 处理现实世界中复杂、精细视觉搜索任务的可靠性。




相关链接:
Galaxy AI #4
科技媒体 Android Authority 通过追踪发现,Samsung 悄然更新了其官方支持文档的脚注内容。这一举动正式确认 Galaxy AI 的基础功能将对符合条件的设备用户永久免费开放,彻底消除了此前市场关于“2025 年后可能转为订阅制”的长期担忧与猜测。
在此次更新前,Samsung Galaxy AI 海外官网的条款曾明确标注“AI 功能免费使用期截至 2025 年底”,并保留了未来保留收费权利的模糊表述。通过 Wayback Machine 网页时光机的存档比对显示,Samsung 现已删除该时间限制说明,并重新修定条款为:“由 Samsung 提供的 Galaxy AI 基本功能是免费的,并将无限期维持免费。”这一政策调整被视为 Samsung 从法律和官方文本层面,正式关闭了对基础 AI 功能收费的可能性。
根据 Samsung 服务条款中对“高级智能”(Advanced Intelligence)的最新定义,此次确认“永久免费”的范围涵盖了目前 Galaxy AI 绝大多数的核心原生体验。具体包含的 13 项核心 AI 功能如下:
- 通话助手 (Call Assist)
- 写作助手 (Writing Assist)
- 图片助手 (Photo Assist)
- 同传 (Interpreter / 翻译助手)
- 笔记助手 (Note Assist)
- 转录助手 (Transcript Assist)
- 浏览助手 (Browsing Assist)
- 绘图助手 (Drawing Assist / 涂鸦助手)
- 照片氛围 (Photo Ambient)
- 今日简报 (Now Brief)
- 音频消除 (Audio Eraser)
- Bixby 智能语音
- 健康助手 (Health Assist)
上述功能已作为 Galaxy S24 系列、Z Fold5 等旗舰机型的内置体验,用户在设备的生命周期内可以持续调用这些由 Samsung 自研或原生提供的端侧及云端混合 AI 服务,无需支付额外订阅费用。
在地区差异方面,Samsung 中国官网的标注目前与海外版本略有细微差别。中国官网目前的条款说明为:“目前用户可免费使用 Galaxy AI 功能,但未来 Samsung 可能将其部分或全部 AI 功能变更为有偿服务;第三方提供的 AI 功能可能适用不同的条款。”
尽管基础套餐已确认“永久免费”,但 Samsung 同时也明确了未来 AI 业务的变现路径。在新版脚注中特别指出,“未来发布的增强型功能(Enhanced features)或新服务可能会以付费形式提供”。这意味着 Samsung 可能会参考其他软件服务的模式,将基础功能作为购机标配,而将更高级、更复杂的 AI 计算能力划归为增值服务。
此外,条款中严格区分了“Samsung 原生功能”与“第三方功能”。例如,目前广受欢迎的“即圈即搜(Circle to Search)”功能由 Google 提供技术驱动,Samsung 明确其属于第三方服务,并不在 Samsung 承诺的“基础功能永久免费”范围内。这类功能未来的资费政策将完全取决于 Google 等合作方的决定。
回顾此事的背景。早在 2025 年 7 月的 Galaxy Unpacked 发布会上,Samsung 高层就曾公开表态“暂无计划对默认 AI 体验收费”。此次官方文档的修订,标志着该承诺已从口头表态落实为官方服务政策。在当前全球科技行业 AI 服务日益“会员化”和“订阅化”的趋势下,Samsung 此举强化了其 Galaxy 品牌高端机型的长期持有机价值。


相关链接:
- https://www.samsung.com/us/support/answer/ANS00000000000000000000000000000000/
- https://www.samsung.com/global/galaxy/galaxy-ai/
- https://www.samsung.com/us/support/galaxy-ai/
- https://www.samsung.com/global/galaxy/galaxy-ai/terms/
- https://www.samsung.com/us/support/galaxy-ai/terms/
- https://www.ithome.com/
- https://android.ithome.com/
- https://www.aibase.com/zh/news/24612
Grok #5
Delving Into the Details
I'm now focusing on the meticulous level of detail required, aiming for complete, lossless reconstruction. I'm actively avoiding summarization or information compression, as I want the final result to be comprehensive and precise. I'm also ensuring the retention of all limiting qualifiers and avoiding any alteration or translation of proper nouns, company names, or technical terms.
Parsing the Parameters
I'm now zeroing in on the specific restrictions and their scope. The announcement from @Safety is clear, with a focus on editing and generating images of real people. I'm noting the implications for free and paid users, as well as the geo-specific limitations, and the involvement of California's Attorney General. The aim is to capture every detail.
Focusing on Fine-Grained Accuracy
I'm now carefully processing the provided data. I've noted the background context, the official announcement from @Safety, and the core restrictions. I'm taking care to include every detail, even specifying the types of clothing prohibited, the details of the investigation, and the technical explanations given. I'm also meticulously recording the key terms.
Constructing a Narrative
I'm now carefully constructing the detailed account, starting with the announcement from @Safety. My focus is on ensuring every nuance is captured, including the specific limitations on editing images of real people, the scope of the restrictions across user types, and the role of California's Attorney General. I'm meticulously incorporating all numerical data and key terms.
在持续数周的舆论风暴与严峻的监管压力下,X平台(原Twitter)于2026年1月15日凌晨通过其官方安全账号@Safety正式宣布,对其旗下的AI模型Grok实施史上最严格的图像生成与编辑功能限制。此次调整直接回应了近期多起关于Grok生成涉及儿童“性化”图像、未经同意的裸露内容以及针对现实人物隐私侵犯的严重指控。
根据最新公布的技术限制政策,Grok已彻底禁止对任何现实人物(real people)的照片进行二次编辑。这一禁令具有极高的针对性,系统将从底层算法逻辑上严禁将他人照片修改为身着比基尼、内衣或其他任何形式暴露服装的形象。X平台在声明中明确承诺:“Grok AI不会再将真人的照片改成‘比基尼照’。”此项针对编辑权限的限制适用于平台上的所有用户群体,没有任何例外,即便是支付了订阅费用的高级会员也将受到同样的约束。
除了编辑功能的收紧,xAI决定对图像生成功能的访问权限进行重大调整。目前,图像生成功能已全面进入“付费墙”模式,所有的非订阅用户将完全丧失调用Grok生成任何图片的权限。为了应对不同法域的合规性要求,在法律明确禁止此类AI行为的特定地区(例如美国加州),xAI已经在系统层面部署了深度的地理围栏限制,直接屏蔽所有关于“现实人物身穿比基尼或内衣”类图像的生成能力,旨在从源头杜绝违规内容的产出。
此次功能的大幅缩减与法律层面的严厉挑战紧密相关。加州总检察长Rob Bonta已针对Grok在处理儿童剥削材料方面的安全漏洞启动了正式调查。根据其披露的一项针对xAI生成内容的独立分析报告显示,在2025年圣诞节至2026年新年期间,该系统生成的约2万张图像中,超过半数(50%以上)包含了极度暴露的人物形象。更令监管部门担忧的是,这些图像中不乏疑似未成年人的内容,这引发了社会各界对AI平台内容安全审查机制的重大质疑。
针对上述指控,Elon Musk此前曾公开辩称,他对Grok能够生成未成年人裸露图像的情况“毫不知情”。他进一步给出技术解释称,相关的生成功能理论上仅在用户主动开启NSFW(成人内容)选项时才保持可用,且生成范围应被严格限制在“虚构的成年角色”之内。Elon Musk将Grok的尺度标准参照定位于Apple TV上的R级电影。然而,面对日益严峻的合规形势,他也承认系统必须根据全球各地的具体法律环境,动态且实时地调整限制策略。
在最新的官方声明中,X平台重申了其对儿童剥削行为“零容忍”的坚定立场,并表示将持续开展大规模的清理行动,重点打击包括儿童性虐待材料(CSAM)和未经同意的裸露内容在内的高危信息。尽管采取了紧急补救措施,但此次风波依然暴露了生成式AI在快速部署过程中面临的伦理边界与安全治理难题。当技术迭代的速度超过监管与安全防护机制的构建速度时,如何通过技术手段平衡AI的创造力与社会安全性,已成为xAI及所有大模型开发者必须正视的核心命题。


相关链接:
Grok 4.20 #6
Evaluating Tech Commentary
I'm currently sifting through Elon Musk's recent remarks concerning Grok 4.20's performance versus Anthropic's Opus 4.5. My focus is on maintaining precise details, ensuring no critical information is lost in translation. I am also prioritizing technical accuracy, adhering strictly to proper names and terminology. The current strategy involves retaining the original wording where feasible, and restructuring the information so it reads well.
Processing Musk's Statements
I've just finished processing Elon Musk's statements regarding Grok 4.20 and Opus 4.5. I'm now structuring the information, adhering to the atomic facts approach. I've retained the original wording for key terms like "Grok," "Opus 4.5," and "xAI." The focus is on a multi-paragraph structure, ensuring the accurate representation of API parameters, relative timelines, and attributions, devoid of personal opinions.
Summarizing the X Exchange
I'm now incorporating Elon Musk's replies to the benchmark data. The initial paragraph outlines the context, referencing the X user's shared charts comparing the models, with particular focus on Anthropic's Opus 4.5. Subsequent sections will address Musk's reactions, starting with his prediction on Grok 4.20's performance, while extracting the technical admissions.
Detailing Musk's X Comments
The core of my analysis is now structured, following the established paragraph guidelines. I've initiated with the user's benchmark charts, setting the stage, and included Musk's prediction about Grok 4.20's performance. The subsequent sections will detail his admission regarding coding, the "cut off" situation with Anthropic, and the resulting strategic shift, including the "Karma" comment. Key terms remain untranslated and I'm ensuring all specifics are retained.
Synthesizing xAI Remarks
I'm now building the narrative using the provided components, focusing on context, reactions, admissions, conflict, and strategy. I'm prioritizing accuracy in all technical aspects, retaining names like "Grok 4.20" and "Anthropic" as well as the key concepts of the "cut off" and "Karma". My goal is to synthesize these details into multiple, concise paragraphs.
Refining xAI Reporting
I'm now structuring the narrative, incorporating the X user's benchmark chart as the initiating event. Elon Musk's replies, including his Grok 4.20 prediction and technical acknowledgements, are being integrated. I'm focusing on "cut off" details and the "Karma" remark, ensuring key terms like "Grok," "Anthropic," and "Opus 4.5" remain untranslated. I'm prioritizing accuracy and a multi-paragraph structure.
Elon Musk 针对 X 平台用户发布的 Opus 4.5 基准测试图表进行了公开回应,并对 xAI 旗下一代大模型 Grok 4.20 的研发进度与性能目标进行了展望。在讨论模型性能对比时,Elon Musk 明确预测 Grok 可能会在 v4.20 版本中展现出更佳的表现,并对这一版本的前景持有「拭目以待」的乐观态度。
在回应过程中,Elon Musk 罕见地对竞争对手 Anthropic 在技术领域的积累表示了认可。他直言不讳地承认,在现阶段的程式设计(Programming/Coding)维度上,即将推出的 Grok 4.20 与 Anthropic 的模型相比「可能还差一点」。Elon Musk 进一步评价称,Anthropic 在编码领域确实「做了一些特别的事情」,这使得其模型在处理代码生成与逻辑构建等特定任务时具备了目前的竞争优势。
针对双方的竞争背景,Elon Musk 透露了一个关键的信息。他指出,Anthropic 近期对其竞争对手实施了严格的准入限制,禁止其他 AI 开发商使用其模型资源。Elon Musk 证实 xAI 曾被 Anthropic「切断」(cut us off)了某种形式的合作关系或资源访问权限。然而,他并未将此视为研发障碍,反而认为这种封锁成了一个「有益的激励因素」,迫使 xAI 团队在独立研发上更具动力。
此外,Elon Musk 在评论中还带有讽刺意味地提到,Anthropic 这种主动切断资源访问的行为「对他们的业力(Karma)来说不太好」。尽管他公开承认了 Grok 目前在代码生成方面的短板,但他强调 Grok 4.20 的设计核心目标并非仅局限于单一维度的性能争霸。根据他的表态,xAI 的研发策略是让 Grok 4.20 在「其他领域表现卓越」(excel in other areas),力求通过综合能力的提升来实现在 AI 领域的竞争定位。
目前,xAI 团队正致力于 Grok 4.20 的开发工作,Elon Musk 的此次发言也明确了该版本的发布预期以及在大模型横向评测中的战略取舍。即便在编码领域暂时落后于 Anthropic 的 Claude 系列,xAI 仍计划通过其他功能维度的突破来确保 Grok 4.20 的市场竞争力。
相关链接:
- https://x.com/techdevnotes/status/2011572071009226888?s=20
- https://x.com/elonmusk/status/2011699395717447749?s=20
- https://linux.do/t/topic/1463533
Manzano #7
Processing Technical Data
I'm focusing on the global tech news editor's role. I'm trying to figure out how to transform raw information into in-depth, lossless technical reports. Specifically, I'm thinking about preserving the original references such as the names of people, companies, and products (like Manzano and GPT-4o) during the transformation.
Defining Reporting Standards
I'm now detailing the specifics of how to build these tech reports. I've broken it down to preserving specific elements like names and terminology, and how to handle translation. I've also established guidelines on detail, structure, and output format. I'm focusing on the first "atomic" piece of information related to the release date of Manzano and its basic functions.
Constructing Report Sections
I'm currently segmenting the technical details into distinct sections. I've broken down the source information into "atomic" components, such as the release date of Manzano, its core architecture, performance metrics, and application possibilities. I'm focusing on preserving names, terminology, and key data points while formulating a clear narrative structure. The goal is to build a complete report without removing any key information.
Formulating the Atomic Elements
I'm now concentrating on breaking down the source material into those atomic components, focusing on the Manzano model. I've pinpointed the key aspects: its release by Apple, its multimodal nature, the three core components of its architecture (Hybrid Vision Tokenizer, LLM, and Diffusion Decoder), performance metrics (like the "bird under elephant" example and comparisons to GPT-4o and Nano Banana), functional integrations (depth estimation, style transfer, and inpainting), and future application in tools like Image Playground. I'm also preparing for the inclusion of the 300M-30B parameter range.
Apple(苹果公司)近期发表了一篇重量级研究论文,正式推出名为 Manzano 的多模态 AI 模型。该模型的核心突破在于成功打破了长期以来人工智能领域在“视觉理解”与“图像生成”之间的技术壁垒,实现了两项功能的深度有机融合。
在传统的技术框架下,模型往往难以兼顾理解与生成:擅长分析图像内容的视觉理解模型通常偏好连续的数据流,而专注于从文本创作高质量图片的图像生成模型则依赖离散的数据块。这种数据处理偏好的差异导致模型在同时处理两项任务时容易产生冲突,迫使开发者在图像质量与理解深度之间进行妥协。
为了彻底解决这一难题,Manzano 引入了一种创新的三段式“双修”架构。该架构的第一层是“混合视觉分词器”(Hybrid Vision Tokenizer),它能够通过独特的设计同时生成连续和离散的视觉表示,为后续处理奠定基础;第二层利用强大的大语言模型(LLM)来预测图像的语义内容;最后,由“扩散解码器”(Diffusion Decoder)负责完成像素级的精细渲染。这种设计确保了 Manzano 在理解与生成两个维度上都能保持卓越性能,实现近乎无损的功能融合。
在实际性能测试中,Manzano 展现出了顶尖的逻辑理解力,尤其是在处理违反常规物理常识和复杂空间关系的指令时表现惊人。研究人员以“一只鸟在大象下方飞翔”这一反直觉指令进行测试,结果显示 Manzano 的逻辑准确性已足以媲美 OpenAI 的 GPT-4o 以及 Google 的 Nano Banana 模型。此外,实验数据证实,随着模型规模的扩大,其性能提升依然显著。Manzano 具备极高的灵活性,支持从 3 亿参数到 300 亿参数(300M - 30B)的跨度扩展。
除了核心的视觉理解与文本生成图像功能外,Manzano 还展现了处理多种复杂专用任务的能力,包括深度估计(Depth Estimation)、风格迁移(Style Transfer)以及图像修复(Image Inpainting)。
尽管 Manzano 目前仍处于研究阶段,尚未直接应用于商用硬件,但 Appleinsider 等科技媒体认为,该技术的成熟预示着 Apple 在构建强大底层 AI 基础架构方面的雄心。未来,这项技术极有可能被整合进 iPhone 和 Mac 等端侧设备的系统功能中,特别是 Apple 即将推出的“图乐园”(Image Playground)等创意工具。通过强化底层 AI 的绘图与修图能力,Manzano 有望为用户提供更智能、更具想象力的创作体验,并进一步巩固 Apple 在端侧 AI 领域的竞争优势。
相关链接:
- https://machinelearning.apple.com/research/manzano
- https://www.aibase.com/zh/news/24600
- https://www.aibase.com/zh/news/24599



相关链接:
OpenCode Black #8
Defining the Scope
I'm zeroing in on the task parameters now. Thinking about the core requirements: a detailed tech news report editor, and the OpenCode/Claude situation is the focus. Considering how to handle the "no title," "no summaries," and "no external links" directives. I'm noting the need to translate non-technical elements professionally while retaining English terms.
Mapping and Contextualizing
I'm now clarifying the crucial nuances of the mapping requirements. I'm focusing on "A社" and its implied meaning in the technical context. Considering how to incorporate it, given its absence from the explicit word mapping list. I've re-evaluated and plan to use "Anthropic," but acknowledge the implicit reference. I will focus on the most reliable approach for global tech editors. Finally, I will be ready to synthesize.
Structuring the Report
I'm now outlining the news story's structure. I'll open with a concise summary, avoiding a title or external links. I'm focusing on facts: OpenCode's non-profit status, the Crush dispute, Zen's launch, the Black service, promotional releases, and Anthropic's block. I'll use "Anthropic" or "Anthropic (A社)" appropriately, mindful of the mappings and source sentiment. Then I will refine the summary.
Synthesizing the Narrative
I'm now integrating the facts. I'm structuring the report, focusing on OpenCode's non-profit foundation, the Crush issue, the launch of Zen, OpenCode Black's offerings, and promotional releases. I will address Anthropic's block, carefully. I'll open with the non-profit's background and then discuss the monetization shift, highlighting the actions. The implications of Anthropic's block will be considered, following a careful approach.
根据社区及市场最新消息,Anthropic(A社)在其近期推出的安全策略中,针对OpenCode项目实施了极为严苛的技术封锁措施。据多方反馈,Anthropic目前已在其底层安全过滤机制中集成了针对特定关键词的拦截功能,只要用户的Prompt(提示词)中包含“opencode”字样,系统将直接触发Block(阻断)操作,导致对话无法正常进行。
这一针对性动作被认为是对此前OpenCode一系列商业化行为的剧烈回应。OpenCode最初定位为一个非营利项目,曾在去年因与Crush项目之间的复杂纠纷而引发技术社区广泛关注。然而,为了实现项目营利与持续经营,OpenCode随后推出了名为Zen的付费服务。在市场推广阶段,OpenCode采取了部分模型开放免费使用的策略以吸引流量。
就在近日,OpenCode正式发布了名为OpenCode Black的高级订阅方案。该方案定价为每月200美元,其核心卖点是向付费用户提供“全模型任用”的权限。由于OpenCode在开发者群体中具备一定知名度,OpenCode Black方案在发布后迅速获得了大量订单及关注,但也因此引发了模型提供方的警觉。
业内分析指出,此次Anthropic精准封锁“opencode”关键词的举动,事实上印证了此前Claude限制第三方API接入的策略具有极强的针对性。分析认为,Claude禁止第三方平台接入的初衷很大程度上是为了定向遏制OpenCode这种通过转售或封装大模型能力获利的商业变体。在此过程中,其他合规或小规模的第三方开发者及项目可能遭遇了“池鱼之殃”,被涵盖在了泛化的封锁策略内。
目前,Anthropic官方尚未对此特定关键词拦截机制发表公开评论。但从技术实现层面看,这种基于硬编码关键词的阻断反映了其在打击非法转发和违规商业化方面的强硬手段。对于深度依赖Claude模型的第三方服务商而言,这一风向的变化意味着模型提供方与分发渠道之间的博弈已进入白热化阶段。



相关链接:
Step-Audio-R1.1 #9
Synthesizing the Data
I've been meticulously examining the three snippets on the Step-Audio R1.1. My focus is on cross-referencing the information to identify consistencies and discrepancies, particularly concerning the product's technical specifications and target market. I'm now drafting the initial outline, structuring it around key features, such as the audio processing unit and user interface.
Structuring the Analysis
I'm now organizing the technical specifications into logical sections. My process involves meticulously categorizing the information from each snippet, ensuring that I preserve the original English technical terms. I'm prioritizing the Agent and Transformer architecture details, preparing to compare and contrast them across the sources. The goal is to avoid summary and maintain extreme fidelity.
Comparing the Data Points
My focus is now on the discrepancies. I am comparing the dates, and sources provided across the snippets. I'm taking special care when reviewing the technical specifications and reported achievements of the Step-Audio R1.1, ensuring alignment with the original language. The platforms mentioned are under careful scrutiny, particularly ModelScope.
Drafting the Introduction
My immediate task is to craft the introduction. The objective is to concisely present the release of the Step-Audio R1.1 by Stepfun. I'm focusing on incorporating the key details from the initial sources, particularly the release date and the model's primary achievements. I am carefully balancing the need for conciseness with the importance of accurate reporting of technical specifications and company details.
Refining the Structure
I'm now carefully integrating the technical specifications into the relevant sections. My focus is on the "Native Audio Reasoning" and "Audio-native CoT" features, ensuring their placement within the architectural and capability sections. I'm also preparing to incorporate details regarding the real-time streaming inference, and the "Hear and think" aspects of the model. I am paying special attention to the examples: cat sounds and Korean lyrics, ensuring proper integration into the discussion of applications.
Detailing the Architecture
I'm presently focusing on the "Native Audio Reasoning" and "Audio-native CoT" components, meticulously reviewing their roles in the model's functionality. I am cross-referencing their descriptions, paying special attention to how these features contribute to the "Hear and think" capability. I am then carefully drafting sections to maintain the technical accuracy.
Structuring the Report
I'm now focusing on formatting the report for clarity. I'm organizing the information into the pre-defined sections: event overview, benchmark performance, technical architecture, user experience, applications, and release details. I'm also ensuring the consistent usage of technical terminology, such as "Native Audio Reasoning" and "Audio-native CoT," to maintain the technical integrity of the report.
阶跃星辰(StepFun)于2026年1月15日正式发布并开源了其原生语音推理模型 Step-Audio-R1.1。该模型在发布当日即宣布在全球知名的人工智能模型评测榜单 Artificial Analysis Speech Reasoning 中荣登榜首,刷新了语音推理领域的历史最高分纪录。
在 Artificial Analysis 的评测中,Step-Audio-R1.1 凭借 96.4% 的准确率(Accuracy Rate)成为新的 SOTA(State-of-the-Art)模型。这一成绩超越了包括 Grok、Gemini 以及 GPT-Realtime 在内的多款顶级闭源模型。该榜单的评估维度非常全面,涵盖了模型在音频处理、逻辑推理能力的准确率以及响应时间(Response Time)等关键指标。
技术架构层面,Step-Audio-R1.1 采用了原生音频推理(Native Audio Reasoning)方案,实现了端到端(End-to-End)的语音处理能力。其核心技术亮点在于引入了音频原生思维链(Audio-native CoT, Chain of Thought),这使得模型在处理音频任务时,能够跳过传统的中转步骤,直接在音频模态下进行深度推理。这种设计让模型具备了“像人类一样听到对话即思考”的特点,能够在没有额外延迟的情况下理解复杂的语音内容。
在推理性能方面,该模型支持实时流式推理(Real-time streaming inference),实现了“边想边说”的功能。这意味着模型在接收语音输入的同时即可开始生成推理结果,极大地提升了交互的实时性。在阶跃星辰展示的实际应用案例中,Step-Audio-R1.1 展现了极高的语音理解水平,例如它可以精准分析猫咪争斗时的情绪与声音含义,并能深度理解和解析韩语歌词等复杂音频环境下的语义。
关于开放程度与获取渠道,Step-Audio-R1.1 属于完全开源(FULLY OPEN SOURCE)的项目,其模型权重(Open Weight)已同步上传至 HuggingFace 和 ModelScope 社区。开发者和研究人员目前可以免费下载完整的模型权重进行本地部署。同时,ModelScope 为该模型提供了在线演示(Online Demo)环境,方便用户进行推理体验、模型探索和应用部署。
在未来的产品线规划中,阶跃星辰表示虽然目前用户已可以通过开放的聊天模式体验 Step-Audio-R1.1 的核心流式推理功能,但更为完整的实时语音 API 预计将于2027年2月正式上线。目前,感兴趣的开发者可以前往阶跃星辰开放平台体验中心或 HuggingFace 的 stepfun-ai 仓库获取相关资源。














相关链接:
- https://modelscope.cn/studios/stepfun-ai/Step-Audio-R1
- https://modelscope.cn/models/stepfun-ai/Step-Audio-R1.1/summary
- https://huggingface.co/stepfun-ai/Step-Audio-R1.1
- https://www.aibase.com/zh/news/24617
- https://www.reddit.com/r/LocalLLaMA/comments/1qdd1l7/stepaudior11_open_weight_by_stepfun_just_set_a
- https://x.com/ModelScope2022/status/2011687986338136089
Step3-VL-10B #10
Evaluating New Model Releases
I'm currently digesting information about the Step3-VL-10B model, recently released by Stepfun-AI, as per TKGaming_11's post. Linux.do's contrasting perspective against larger models, including Gemini 2.5P, is also proving insightful. Considering how this impacts existing benchmarks is next.
Investigating Step3-VL-10B
I've taken a deep dive into the official release details. It's clear that the Step3-VL-10B model, a vision-language model with 10 billion parameters, has been launched on Hugging Face. The model is being directly compared against some serious competition: a 235B model, a 106B model, and even Google's Gemini 2.5P.
Assessing the Step3-VL-10B
I'm now consolidating key features: The model, Step3-VL-10B, is from Stepfun-AI. It's a 10B parameter vision-language model, released around January 15, 2026, on Hugging Face. The model's performance, as per Linux.do, is being compared to much larger models, including a 235B and 106B model.
Detailing Model Characteristics
I'm now focusing on specifics. Step3-VL-10B, a 10B parameter vision-language model, released by Stepfun-AI on Hugging Face around January 15, 2026. This model is being directly contrasted against a 235B model, a 106B model, and Gemini 2.5P. User TKGaming_11 alerted the LocalLLaMA community to the release.
Elaborating the Analysis
I'm now focusing on a detailed presentation. Stepfun-AI's Step3-VL-10B, a 10B-parameter vision-language model, released January 15, 2026, on Hugging Face. The model is contrasted with a 235B model, a 106B model, and Gemini 2.5P. User TKGaming_11 alerted the LocalLLaMA community. It is being compared to giants in the field.
Dissecting Stepfun-AI's Release
I'm now piecing together the narrative around Stepfun-AI's Step3-VL-10B, focusing on the release on January 15, 2026. This 10B parameter vision-language model, spotted by TKGaming_11 on Reddit's LocalLLaMA, is available on Hugging Face. Linux.do's commentary highlighting comparisons to 235B, 106B, and Gemini 2.5P models is revealing. The goal is to evaluate the implications of their decision.
Stepfun-AI 在 2026 年 1 月 15 日正式推出了其全新的多模态大模型 Step3-VL-10B,并将其开源至 Hugging Face 平台。该模型的发布信息最早由用户 TKGaming_11 在 Reddit 的 LocalLLaMA 版块共享,引发了极客社区的广泛关注。
Step3-VL-10B 是一款参数量为 10B(100 亿)级别的视觉语言(Vision-Language)模型。尽管其参数规模相对精简,但在官方和技术社区流出的性能对比中,该模型被频繁置于跨量级的竞争维度进行评估。具体而言,Step3-VL-10B 在多项基准测试中被直接拿来与参数量高达 235B 的超大规模模型、106B 规模的模型以及 Gemini 2.5P 进行同屏性能对比。这种“以小博大”的对比策略显示出阶跃在模型效率优化方面的技术信心。
在技术分发方面,Stepfun-AI 将该项目托管于 Hugging Face,仓库路径为 stepfun-ai/Step3-VL-10B。官方在该项目的声明中强调,此举是其推动人工智能民主化以及倡导开源科学(Open Science)旅程中的重要一环。社区开发者对于 Step3-VL-10B 在处理复杂视觉理解任务时的表现给予了高度评价,尤其是在 10B 这一便于本地部署的参数量规模下,其展现出的竞争力被认为可能挑战现有的中大型多模态模型。
根据 Linux.do 等社区的反馈,此次 Step3-VL-10B 的对比对象中出现的“235B 大模型”和“106B 模型”并未在原始信息中明确具体品牌,但其强大的参数背景使 Step3-VL-10B 的表现更具参考价值。目前,该模型已全面开放下载,其开源协议及具体技术文档可在 Hugging Face 的专属页面进行查阅。







相关链接:
千问App #11
Observing AI Advancement
The recent focus has been on the practical application of AI. I'm noting the launch of the "千问App," specifically its capabilities. I see it as a significant milestone, potentially reshaping how complex real-world tasks are handled. The timeline and location of this development are also quite relevant in this analysis.
Analyzing New Functionality
I'm now diving deep into the specific features. The integration with existing platforms like Taobao and Alipay is key. I'm focusing on the "multi-store ordering" functionality, and evaluating its efficiency. The "real-person voice" AI phone ordering aspect is also highly noteworthy.
Investigating Core Competencies
I'm now focusing on the practical application, including "multi-store ordering" on Taobao. The emphasis on real-world utility and integration with existing platforms is truly significant. The provided specifics, such as the "40杯奶茶" example, offer great insight. I'm also examining how AI phone ordering offers a real-person voice. I'm looking at how all of this is done on the backend.
Evaluating Operational Efficiency
I am now focusing on the performance of the "千问App," specifically its integrated "real-person voice" AI phone ordering. The end-to-end process, from user request to order fulfillment, is of particular interest. I'm exploring the implications of the "multi-store ordering" functionality, and its impact on user experience.
Reviewing Functionality Deployment
The focus is now on the newly released "千问App," specifically its capabilities as a comprehensive AI assistant. This release, on January 15th, 2026 in Hangzhou, offers over 400 AI service functions, including "multi-store ordering" and AI-driven purchasing, which I am assessing. I'm focusing on its integration with Taobao and Alipay, and the impact the "real-person voice" AI phone ordering has on the user experience. The scale of the monthly active users is also of interest.
2026年1月15日,阿里巴巴在杭州园区正式宣布千问App迎来重大升级,上线超过400项AI办事功能。这一升级标志着千问App成为全球首个能够完成真实生活复杂任务的AI助手,实现了从“对话工具”向“生产力助手”的跨越。
阿里巴巴副总裁、阿里千问C端事业群总裁吴嘉透露,千问App上线两个月以来,其C端月度活跃用户(MAU)已突破1亿。吴嘉表示,目前发布的版本仅是千问App办事能力的起步阶段,未来的愿景是让用户通过单一App即可完成多项复杂任务,无需在不同应用间频繁切换。
在物理世界办事能力方面,千问App已经全面接入了淘宝、支付宝、淘宝闪购、飞猪、高德、1688、盒马、优酷、大麦娱乐、阿里健康、菜鸟等阿里巴巴旗下的全量生态业务。通过这种深度融合,千问App在全球范围内首次实现了点外卖、购物、订机票、订酒店等全链路AI交互功能,并已向所有用户开放测试。
在发布会现场演示中,吴嘉通过一句指令“帮我点40杯霸王茶姬的伯牙绝弦”展示了其生活服务能力。千问App迅速调用淘宝闪购插件,在无需跳转页面的情况下,直接在端内通过内置的“支付宝AI付”功能完成了支付。随后,淘宝闪购骑手将奶茶送达现场。此外,当面对团建等复杂场景时,千问App能够提供1-3套可选方案,并支持同时在多家店铺下单。千问还展示了具备真人音质的“AI电话”功能,可代用户拨打电话向商家订奶茶或订餐,并能应对复杂的双向沟通。
针对购物决策,千问联合淘宝推出了“一句话购物”能力。过去两个月,用户在千问上主动询问商品推荐的次数环比增长了300%。千问App目前能够基于淘宝的商品数据库和评价体系,深度理解用户的精细需求。例如当用户提出“为父母购买扫地机器人”时,AI能自动推理出“家里有猫”所带动的“防缠绕”和“高温杀菌”等隐含刚需,并直接给出具体的商品推荐及购买入口。
针对政务民生场景,千问App接入了支付宝政务服务,上线了涉及签证、户口、公积金等领域的50项民生服务。用户通过“杭州户口怎么办护照”等自然语言提问,即可获得政策解读、材料清单,并直接触达办理入口。
在数字世界处理方面,千问App同步开启了“任务助理”功能的定向邀测,覆盖移动端和网页端。该功能具备类人化的多步骤规划能力,涉及以下四个核心场景: 1. 应用开发:支持“一句话做应用”,现场通过接收脱敏数据,快速构建了一个抽奖程序。 2. Office办公:具备调用工作工具处理表格的能力。演示中,千问App一次性录入并处理了101张发票,生成的报表支持“启动核查”功能,以便用户进行二次校对。 3. 信息可视化:能将原始文档和杂乱数据提取重点,并转化为可视化的汇报材料。 4. 咨询调研:千问在处理深度报告时,会将指令后台裂变为上百个节点,模拟树状生长搜索。在演示中,千问在8分钟内完成了80多次搜索,生成了一份长达24页的深度研报。
在垂直教育领域,千问推出了“备考大礼包”,涵盖六大核心能力:一句话找卷子、错题举一反三、千问小讲堂、超千万真人讲题、拍照讲题、以及作业批改,为学生提供全流程复习工具。
支撑上述能力的是千问大模型的三大底层技术突破: 1. 全模态理解:使AI具备看懂界面、图文报表,听懂声音并理解意图的能力。 2. AI Coding:依靠大幅提升的代码生成能力,使模型能够实时构建工具解决具体问题。 3. 超长上下文工程:显著提升了处理复杂任务时的交付上限。
吴嘉强调,千问的核心优势在于Qwen最强模型与阿里丰富生态数据的结合。通过利用阿里巴巴独特的交易和服务数据,千问能够有效过滤互联网上的营销噪音,确保AI在购物和办事功能中的客观性与准确性。目前,“任务助理”功能在测试结束后将面向全体用户免费开放。



















相关链接:
维基媒体基金会 #12
Investigating Agreements and Partnerships
I've been meticulously reviewing the articles and snippets concerning the Wikimedia Foundation's agreements. The focus is on the AI content training deals with Microsoft, Meta, Amazon, Perplexity, and Mistral AI, keeping the specific terms and parties involved. I'm taking a deep dive into the technical reporting, following the LongCat protocol.
Analyzing the Deal's Components
I'm now focusing on the specific structures of these deals, examining the "Wikimedia Enterprise" framework mentioned. The core aim is clear: to monetize Wikipedia content by granting AI firms access for training. I'm noting the strategic shift toward revenue generation and the key players involved, maintaining strict adherence to the facts.
Refining Deal Details
I'm now zeroing in on the specific details, like the 2026 announcement date, and the "Wikimedia Enterprise" framework. My analysis is breaking down the deal's structure, focusing on the core objective: to convert AI firms' reliance on Wikipedia into a revenue stream for the Foundation. The inclusion of new partners such as Perplexity and Mistral AI, alongside existing ones, is particularly interesting. I am considering the "Enterprise" access.
Summarizing Key Partnerships
I am now structuring my analysis around the recent announcement by the Wikimedia Foundation. I'm taking the draft text, and focusing on the core aspects: deals with Microsoft, Meta, Amazon, Perplexity, and Mistral AI. I am ensuring that the strategic aim of monetization is clearly emphasized, along with the "Wikimedia Enterprise" framework.
Revising Partnership Descriptions
I'm now revising the draft text. I'm focusing on key points: the January 15, 2026 announcement, and the partnerships with Microsoft, Meta, Amazon, Perplexity, and Mistral AI, all designed for AI content training. I'm taking careful note of which companies were enlisted in the past, or in the last year, and I'm ensuring the "Wikimedia Enterprise" access framework is clearly defined, and all terms like "AI" and company names are maintained. I'm aiming to keep all details clear.
Wikimedia Foundation 于 2026 年 1 月 15 日(周四)正式宣布,已与 Microsoft、Meta 以及 Amazon 等多家全球科技巨头达成人工智能(AI)内容训练合作协议。这一系列协议的签署,标志着这家运营 Wikipedia 的非营利机构在商业模式变现上迈出了关键一步,旨在将科技企业对 Wikipedia 开放内容的长期依赖转化为实际的机构收入。
根据公开的合作细节,Wikimedia Foundation 在过去的一年内持续拓展其服务对象,不仅签下了人工智能领域的高增长初创公司 Perplexity,还与来自法国的 AI 企业 Mistral AI 达成的合作。此外,在此次集中披露前,Meta 和 Amazon 就已经作为合作伙伴加入了该计划。
这些科技巨头通过支付费用,获得了针对 Wikipedia 内容的“企业级”(Enterprise)访问权限。Wikimedia Foundation 通过这种方式,为需要大规模抓取或调用数据进行 AI 模型训练的公司提供更高效、更稳定的数据接口。早在 2022 年,该基金会就已经开启了这一模式,并与 Alphabet 旗下的 Google 达成了早期的内容合作协议。
此次披露的合作关系覆盖了多家市值领先的技术运营商,包括 Microsoft(股票代码:MSFT.O)、Meta(股票代码:META.O)、Amazon(股票代码:AMZN.O)以及 Google 所在的母公司 Alphabet(股票代码:GOOGL.O)。这些合作协议的达成,被业界视为非营利组织在保障开源精神的同时,探索可持续财务增长途径的重要里程碑,确保了 Wikimedia Foundation 能够从其被广泛用于大规模 AI 训练的数据资源中获得公平的经济回报。






相关链接:
- https://www.reuters.com/business/retail-consumer/wikipedia-owner-signs-microsoft-meta-ai-content-training-deals-2026-01-15/
- https://m.economictimes.com/tech/technology/wikipedia-owner-signs-on-microsoft-meta-in-ai-content-training-deals/amp_articleshow/126542119.cms
- https://www.theverge.com/news/862109/wikipedia-microsoft-meta-perplexity-ai-training-wikimedia-foundation
- https://www.cnbeta.com.tw/articles/tech/1545454.htm
提示:内容由AI辅助创作,可能存在幻觉和错误。